大数据课程笔记 Day18 数据处理与存储支持服务解析
在数据驱动的时代,数据处理与存储支持服务构成了大数据技术栈的基石。Day18的课程重点探讨了这两大核心领域的关键技术、架构设计及实践应用,旨在构建高效、可扩展且可靠的数据基础设施。
一、数据处理支持服务
数据处理涵盖数据从原始形态到可分析状态的整个生命周期,主要包括数据采集、清洗、转换与集成。
- 数据采集与流处理
- 批量采集:适用于非实时场景,如使用Sqoop从关系数据库导入HDFS,或通过Flume收集日志文件。
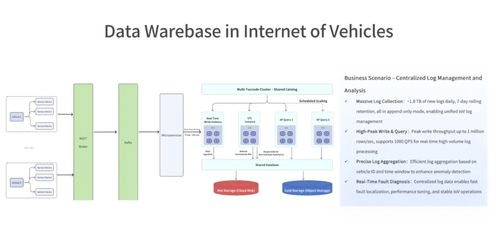
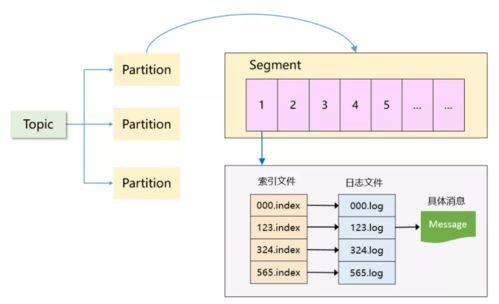
- 实时流采集:应对高时效性数据,常用Kafka作为消息队列,实现数据缓冲与异步处理;结合Flink或Spark Streaming进行实时计算,支持事件时间处理与状态管理。
- 技术要点:需关注数据源适配、吞吐量优化和端到端延迟控制,例如通过Kafka分区并行提升消费能力。
- 数据清洗与转换
- 质量规则:定义完整性、一致性、准确性校验规则,如使用Apache Griffin进行数据质量监测。
- ETL/ELT流程:传统ETL(如Talend)在提取后转换,适用于结构化数据;现代ELT依托云数据仓库(如Snowflake)先加载后转换,提升灵活性。
- 工具生态:Airflow或Dagster用于编排复杂工作流;dbt(Data Build Tool)支持SQL-centric的转换,促进团队协作。
- 数据集成与湖仓一体
- 数据湖:以Delta Lake、Apache Iceberg为代表的表格格式,在对象存储上提供ACID事务、模式演进能力,解决数据孤岛问题。
- 湖仓融合:结合数据湖的灵活性与数据仓库的性能,如Databricks Lakehouse架构,支持BI、ML等多工作负载。
二、数据存储支持服务
存储系统的选择直接影响数据访问效率、成本及治理能力。
- 分布式文件系统
- HDFS:仍是大批量数据存储的基石,适合顺序读写,但面临小文件治理挑战。
- 云对象存储:如AWS S3、Azure Blob Storage,提供无限扩展、高耐久性及低成本,成为数据湖的主流底座。
- 优化策略:通过合并小文件、使用ORC/Parquet列式格式提升查询性能;生命周期策略自动化冷热数据分层。
- NoSQL数据库
- 键值存储:Redis用于缓存与会话管理;DynamoDB支持高并发读写,适配微服务架构。
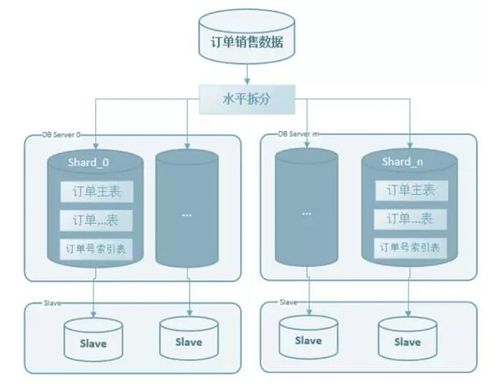
- 宽列存储:Cassandra、HBase适合时间序列或稀疏数据,提供可线性扩展的写入能力。
- 文档存储:MongoDB的灵活模式适用于半结构化数据,如JSON文档。
- 选型考量:依据数据模型、一致性要求(CAP定理)及访问模式(点查询vs范围扫描)进行选择。
- 数据仓库与OLAP引擎
- MPP数据仓库:如Redshift、BigQuery,利用列存储与向量化执行加速分析查询。
- OLAP引擎:ClickHouse、Doris以极速聚合查询见长;Presto/Trino实现跨源联邦查询,避免数据移动。
- 趋势:云原生、存储计算分离成为标配,支持弹性扩缩容与按需计费。
三、架构实践与演进
- Lambda与Kappa架构:Lambda结合批流处理,保证数据一致性但维护复杂;Kappa以流处理为核心简化链路,依赖状态管理与事件溯源。
- 数据网格(Data Mesh):倡导领域导向的去中心化数据所有权,通过数据产品化与自助基础设施提升协作效率。
- 运维与监控:利用Prometheus监控集群健康度;通过数据血缘(如Apache Atlas)追踪数据流转,保障合规性。
###
数据处理与存储支持服务的设计需紧密对齐业务目标:实时场景优先流处理与低延迟存储;探索性分析侧重数据湖的灵活性;报表应用依赖高性能数仓。随着存算分离、智能分层及开源标准化(如OpenTableFormat)的深化,数据基础设施将更趋弹性、经济与自动化。掌握这些核心服务,是构建健壮大数据平台的关键一步。
如若转载,请注明出处:http://www.gimicloud.com/product/1.html
更新时间:2026-06-15 00:15:21