栈空间与堆空间 数据存储机制及数据处理与存储支持服务
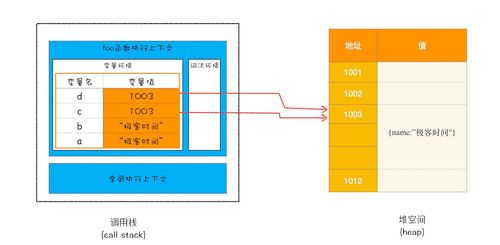
在计算机科学中,程序运行时数据的高效管理是系统性能的基石。栈空间(Stack)和堆空间(Heap)是内存管理中两个核心区域,它们共同支撑着数据处理与存储的底层服务。理解它们的差异和运作方式,对于开发高效、稳定的软件至关重要。
一、栈空间:有序、自动的内存管理
栈空间是一种线性数据结构,遵循后进先出(LIFO)原则,主要用于存储局部变量、函数参数和返回地址等。其特点包括:
- 自动分配与释放:当函数被调用时,相关数据被压入栈;函数执行完毕,数据自动弹出,无需手动干预。
- 速度快:由于内存地址连续,访问效率高,但空间有限,通常较小。
- 确定性:生命周期与函数调用绑定,避免内存泄漏风险。
例如,在C++中,一个函数内定义的整型变量就存储在栈上,函数结束后即被清除。
二、堆空间:动态、灵活的内存分配
堆空间用于动态内存分配,允许程序在运行时申请和释放任意大小的内存块。其特点包括:
- 手动管理:开发者需显式分配(如使用malloc或new)和释放内存,否则可能导致内存泄漏或碎片化。
- 容量大:空间相对充裕,但访问速度较慢,因为地址不连续。
- 灵活性高:适合存储生命周期不确定或大型数据,如对象、数组等。
例如,在Java中,通过new关键字创建的对象通常存放在堆中,由垃圾回收器自动清理。
三、数据处理与存储支持服务
栈和堆的协同工作,为上层的数据处理与存储支持服务提供了基础:
- 运行时环境:如Java虚拟机(JVM)或.NET CLR,利用栈管理方法调用,堆管理对象实例,实现高效执行。
- 数据库系统:内存缓存(如Redis)常结合堆栈机制优化数据访问;事务处理中,栈用于跟踪操作,堆存储临时结果。
- 云计算与大数据:分布式存储服务(如Hadoop HDFS)在底层依赖堆式内存分配处理海量数据;容器技术(如Docker)则通过栈隔离进程资源。
- 编程语言支持:高级语言(如Python、JavaScript)隐藏了栈堆细节,通过解释器或引擎自动管理,提升开发效率。
栈空间和堆空间是数据存储的双支柱,前者以速度和自动化见长,后者以灵活性和容量取胜。在现代计算中,它们与各类数据处理服务深度融合,从操作系统到云端应用,共同构建了可靠、可扩展的存储生态。开发者需根据场景合理选择,以优化性能并规避风险,从而推动技术创新。
如若转载,请注明出处:http://www.gimicloud.com/product/12.html
更新时间:2026-06-19 08:55:19