从架构到服务 NoSQL数据存储与处理的基础演变
随着互联网应用的爆炸式增长和数据结构日益复杂,传统关系型数据库在应对海量数据、高并发访问和灵活数据模型方面的局限性逐渐显现。NoSQL(Not Only SQL)应运而生,它不仅是一种数据库技术,更代表了一种全新的数据存储、处理与应用架构的设计哲学。其发展演变深刻影响了数据处理和存储支持服务的形态与范式。
一、NoSQL基础:核心理念与分类
NoSQL的核心在于摆脱传统关系型数据库的严格模式(Schema)、ACID事务和SQL查询的束缚,追求更高的扩展性、灵活性和性能。根据数据模型的不同,主要分为以下几类:
1. 键值存储(如Redis、DynamoDB):结构简单,通过唯一键访问数据,适合缓存、会话存储等场景。
2. 文档数据库(如MongoDB、Couchbase):以JSON/BSON等格式存储半结构化文档,模式灵活,适合内容管理、用户配置等。
3. 列族数据库(如HBase、Cassandra):按列族存储数据,适合海量数据的分布式存储与查询,常见于大数据分析。
4. 图数据库(如Neo4j):以节点、边和属性存储数据,专门优化了关系查询,适用于社交网络、推荐系统等。
这些类型为不同应用场景提供了针对性的解决方案,奠定了数据处理多样化的基础。
二、应用架构的演变:从集中到分布式
NoSQL的兴起直接驱动了应用架构的深刻变革。
- 单体架构的解耦:传统单体应用常与单一关系数据库紧密耦合。NoSQL数据库的多样性允许开发者根据微服务或功能模块的具体需求(如高读写、复杂关系、快速缓存)选择最合适的数据存储,推动了服务化与数据解耦。
- 分布式架构的普及:大多数NoSQL数据库天生为分布式设计,支持数据分片(Sharding)和副本复制(Replication)。这使得应用架构能够轻松实现水平扩展,通过添加更多廉价服务器来应对增长,而非依赖单一大型服务器的垂直升级。
- 多模型与混合持久化:现代复杂应用很少只使用一种数据库。架构上常采用“混合持久化”策略,例如用Redis处理高速缓存和会话,用MongoDB存储核心业务文档,用Neo4j管理社交关系。这要求架构设计具备清晰的边界和数据同步策略。
三、数据存储与处理的演变:从单一到融合
数据处理范式随着NoSQL的发展而不断演进。
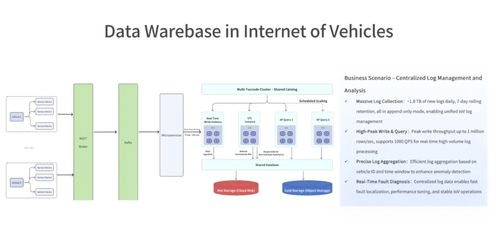
- 存储与计算的分离:早期Hadoop生态(HDFS存储 + MapReduce计算)已体现了存储与计算分离的思想。现代云原生NoSQL服务(如Amazon S3 + Athena,或Snowflake架构)将这种分离推向极致,允许独立扩展存储层和计算层,提升了资源利用率和成本效益。
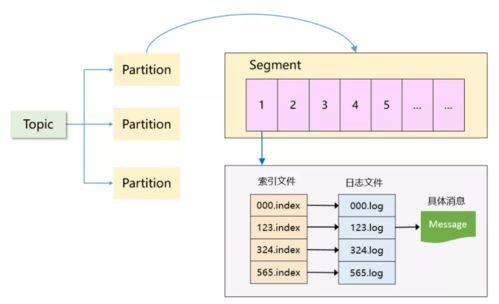
- 从批处理到实时流处理:传统数据仓库侧重于T+1的批处理。以Apache Kafka为代表的消息队列与NoSQL数据库(如Cassandra)结合,构建了实时数据管道,支持流式处理(如Apache Flink、Spark Streaming),实现了事件驱动架构和实时分析。
- 事务与一致性的新平衡:NoSQL早期常牺牲强一致性(ACID)换取可用性与分区容错性(遵循CAP定理)。但NewSQL(如Google Spanner、TiDB)和部分NoSQL数据库(如MongoDB支持多文档事务)开始寻求在分布式环境下提供更强的一致性保证,以满足金融、交易等场景的需求。
四、数据处理和存储支持服务的崛起
NoSQL的普及催生并重塑了整个数据处理和存储的支持服务生态。
- 云托管数据库服务(DBaaS):AWS DynamoDB、Azure Cosmos DB、Google Cloud Firestore等全托管服务,将NoSQL数据库的运维复杂性(如扩缩容、备份、打补丁)完全抽象,开发者只需关注数据模型和API,极大提升了开发效率。
- 数据即服务平台:云厂商提供从数据摄取、存储、处理到分析的一站式平台。例如,数据可通过Kafka流入,存储在对象存储或NoSQL数据库中,由无服务器函数(如AWS Lambda)或流处理服务进行转换,最终结果可被可视化工具查询。这种服务化集成简化了数据流水线的构建。
- 运维与监控服务的智能化:围绕NoSQL集群,涌现出专业的监控、备份、迁移和安全服务。这些服务利用AI进行性能调优、异常检测和容量预测,保障了大规模数据系统的稳定运行。
NoSQL的学习不仅是掌握几种数据库技术,更是理解一种以应用需求为导向、面向分布式和云环境的数据管理思维。从基础的数据模型选择,到宏观的微服务与混合持久化架构,再到与实时处理和云服务的深度融合,NoSQL的演变轨迹清晰地指向了未来:数据处理与存储将越来越作为一种可组合、弹性伸缩、高度自动化的基础服务,无缝地支撑起智能时代的多元化应用创新。
如若转载,请注明出处:http://www.gimicloud.com/product/14.html
更新时间:2026-06-19 00:13:40