Apache Hudi 统一批处理和近实时分析的存储与服务引擎
随着数据规模的爆炸式增长和业务对时效性要求的不断提升,数据处理领域长期存在的批处理与流处理之间的鸿沟,正成为企业构建高效数据湖和数据仓库的关键瓶颈。传统架构通常需要为批处理任务(如T+1报表)和近实时分析(如分钟级监控仪表板)维护两套独立的存储和处理流水线,这不仅带来了高昂的运维成本和数据冗余,更导致了数据一致性与时效性的挑战。Apache Hudi(Hadoop Upserts Deletes and Incrementals)应运而生,其核心目标正是为了弥合这一鸿沟,通过提供统一的存储层和一套服务化能力,在一个数据湖平台上同时满足大规模批处理和高吞吐、低延迟的近实时分析需求。
一、核心设计理念:统一存储,分层服务
Apache Hudi的设计哲学并非简单地合并两种处理范式,而是在存储层面进行根本性的创新,使其原生支持高效的更新、删除和增量查询。其核心在于:
- 表格式抽象:Hudi在分布式文件系统(如HDFS、S3)之上定义了一种具有事务保证的“表”格式。它将数据组织为基础文件(如Parquet)和增量日志文件(如Avro),通过巧妙的元数据管理和索引机制,实现了对海量数据集的记录级插入、更新和删除。这是打破批流存储壁垒的基础。
- 两种表类型:为了灵活适配不同场景,Hudi提供了两种表类型。
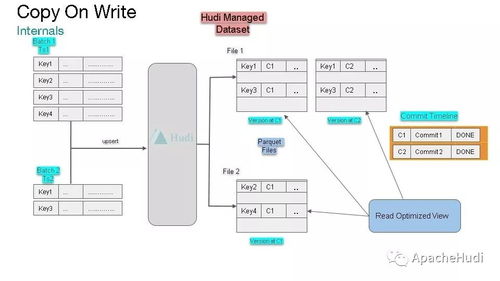
- Copy-On-Write表:在写入时直接合并更新数据到新版本的基础文件中。读操作始终读取最新的、已合并的文件,因此读取性能最优,适用于读多写少、对读取延迟敏感的分析场景。
- Merge-On-Read表:将更新数据先写入增量日志文件,在读取时或后台异步合并到基础文件。这极大地优化了写入延迟,使数据能在几秒内可见,非常适合于写入密集的近实时摄取管道,同时对读取性能有一定妥协。
通过选择不同的表类型和配置,用户可以在同一套存储上,为批处理作业提供高性能的全量扫描,为流式分析提供毫秒到秒级延迟的增量数据流。
二、数据处理:无缝衔接批流计算引擎
Hudi的强大之处在于其与主流大数据计算引擎的深度集成,为数据处理提供了统一的服务接口。
- 增量处理范式:Hudi首创了“增量查询”概念。用户可以轻松查询自某个时间点或提交以来发生变化的所有记录,而无需扫描全表。这为构建高效的增量ETL管道、流计算作业(如Flink、Spark Structured Streaming)以及增量数据同步提供了原子性支持,极大地减少了计算资源消耗。
- 多引擎原生支持:Hudi与Apache Spark、Flink、Trino/Presto、Hive等计算框架深度集成。无论是使用Spark进行大规模的批处理转换,还是使用Flink进行持续的流式摄入,亦或是通过Presto进行交互式SQL查询,都能以一致的方式操作Hudi表,享受到事务性、增量拉取等特性。
- 灵活的写入模式:支持UPSERT(插入更新)、INSERT、BULK_INSERT等多种写入模式,能够优雅地处理CDC(变更数据捕获)数据、数据库日志、以及流式事件数据,简化了数据入湖的复杂度。
三、存储支持服务:保障数据湖的可靠与高效
除了核心的读写功能,Hudi内置了一系列“服务”,将数据湖的运维和管理能力平台化。
- 自动清理服务:Hudi可以自动管理数据文件的版本,清理过期的旧文件快照和不再需要的中间文件,在保障时间旅行查询能力的有效控制存储成本。
- 聚类服务:随着时间的推移,频繁的更新和插入可能导致小文件激增和存储布局碎片化。Hudi的聚类服务可以在后台自动或按需重组数据文件,优化其大小和排序,从而显著提升后续查询的读取性能。
- 索引服务:Hudi维护着高效的全局索引(如布隆过滤器索引、HBase索引等),能够快速定位一条记录存在于哪个文件,这是实现高效UPSERT和点查的关键,避免了为更新少量数据而重写整个分区的开销。
- 并发控制:支持乐观锁机制,允许多个写入器并发地向同一张表提交数据,保障了数据一致性,提升了数据摄取的吞吐量。
- 元数据时间线:所有对表的操作(提交、压缩、清理)都被记录在元数据时间线中,提供了清晰的数据沿袭和审计跟踪,并支持强大的“时间旅行”查询,可以轻松查询任意历史时间点的数据快照。
四、应用场景与价值
Apache Hudi的统一架构在实际应用中展现出巨大价值:
- 近实时数据湖:将来自Kafka等消息队列的流式数据以低延迟(秒级)摄入数据湖,并立即供下游的交互式查询和增量报表使用。
- 增量ETL与CDC处理:高效同步业务数据库的变更到数据湖,仅处理变化部分,构建高效的数据仓库ODS层。
- 统一数据分析平台:在一个平台上同时运行T+1的批处理报表任务和分钟级的运营分析看板,消除数据冗余和不一致。
- 机器学习特征库:为机器学习提供可追溯、可高效更新的特征存储,支持特征的回填与实时更新。
结论
Apache Hudi通过其创新的存储格式和内置的服务化能力,成功地将批处理的高吞吐能力与流处理的低延迟优势融合于一体。它不仅仅是一个存储格式,更是一个功能完备的数据湖服务平台。通过将复杂的文件管理、索引维护、数据优化等任务从应用层下沉到存储层,Hudi极大地简化了数据架构,使开发者和数据工程师能够更专注于业务逻辑,从而在数据规模与时效性要求双双攀升的今天,构建出更简洁、更高效、更经济的一体化数据处理平台。
如若转载,请注明出处:http://www.gimicloud.com/product/13.html
更新时间:2026-06-19 14:43:13