华为HCIP-Big Data学习笔记(二) 大数据离线处理场景化解决方案之数据处理与存储支持服务
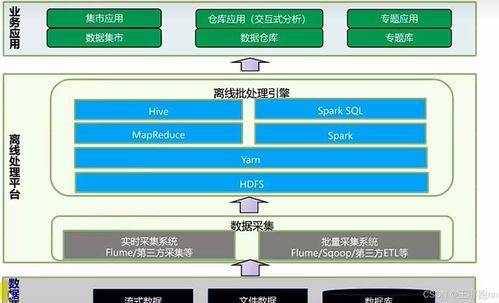
在大数据离线处理的复杂生态中,数据处理与存储支持服务构成了整个解决方案的基石。它们是数据从原始状态流向价值洞见的关键支撑层,确保了离线批处理任务的可靠、高效与可管理。本章将深入探讨华为FusionInsight HD平台在此领域提供的核心服务组件。
1. 数据采集与传输:Flume与Loader
离线处理的第一步是将分散的数据汇聚到统一的数据湖或仓库中。华为平台主要集成和增强了以下服务:
- Flume:一个高可靠、高可用的分布式海量日志采集、聚合和传输系统。其核心优势在于基于流式数据的简单灵活架构,通过配置Source、Channel、Sink即可实现从Web服务器、应用日志等数据源到HDFS、HBase等目的地的稳定传输,非常适合处理实时产生的日志类数据。
- Loader:华为提供的一个数据迁移工具,它实现了关系型数据库(如Oracle, MySQL)与Hadoop生态(HDFS, HBase, Hive)之间的双向批量数据导入导出。Loader通过MapReduce作业并行处理数据,支持全量与增量加载,并提供了图形化界面,极大地简化了结构化数据的迁移工作。
2. 分布式存储基石:HDFS与HBase
汇聚后的数据需要可靠的存储底座。
- HDFS (Hadoop Distributed File System):离线处理的默认存储层。它将超大文件分割成块,分布式存储于集群的多个节点上,并提供多副本机制保障数据高容错性。其“一次写入,多次读取”的模型非常契合离线批处理场景,为MapReduce、Spark等计算框架提供了高吞吐量的数据访问能力。华为版本在原有基础上增强了安全特性、NameNode高可用(HA)以及性能优化。
- HBase:构建在HDFS之上的分布式、面向列的NoSQL数据库。它适用于需要随机、实时读写访问超大规模数据集(如海量详单查询、用户画像存储)的场景。HBase通过行键提供快速查询,是离线处理结果存储或作为某些处理过程中间存储的重要选择。
3. 资源管理与作业调度:YARN
YARN (Yet Another Resource Negotiator) 是Hadoop 2.0引入的集群资源管理与作业调度框架,它将资源管理和应用程序监控分离开来。在离线处理场景中:
- ResourceManager (RM):作为集群资源的全局管理者,负责处理客户端请求、启动/监控ApplicationMaster、以及协调各个NodeManager的资源分配。
- NodeManager (NM):每个节点上的代理,负责管理单个节点上的资源(CPU、内存)和容器(Container)生命周期。
- ApplicationMaster (AM):每个提交的应用程序(如一个MapReduce作业)独有的管理者,负责向RM申请资源,并与NM协作来执行和监控具体的计算任务。
通过YARN,多种计算框架(MapReduce, Spark, Hive等)可以共享集群资源,高效、有序地运行,避免了资源冲突,是支撑多任务离线批处理的核心。
4. 数据处理引擎:MapReduce与Spark
这是执行离线计算逻辑的核心。
- MapReduce:经典的分布式计算编程模型。它将计算过程抽象为Map(映射)和Reduce(归约)两个阶段,中间通过Shuffle过程连接。其优势在于编程模型简单、容错性强,特别适合处理超大规模数据集的批量计算(如全网日志分析、历史数据统计)。但其多阶段落盘的特性导致迭代计算效率较低。
- Spark:基于内存计算的通用分布式计算框架。它提供了比MapReduce更丰富的操作算子(Transformations和Actions)和更优的执行引擎。通过将中间结果缓存到内存中,Spark在迭代计算(如机器学习算法)、交互式查询等场景下比MapReduce快数十倍。Spark Core是其核心,其上构建了Spark SQL(结构化处理)、Spark Streaming(流处理)等模块,实现了离线与准实时处理的统一。在华为解决方案中,Spark得到了深度集成与性能优化。
5. 数据仓库与SQL化处理:Hive
Hive是基于Hadoop的数据仓库工具,它将结构化的数据文件映射为一张数据库表,并提供类SQL(HiveQL)查询功能。对于熟悉SQL的数据分析师而言,Hive极大地降低了大数据处理的门槛。其本质是将HiveQL语句转换成一个或多个MapReduce或Spark作业在集群上执行。它适用于海量历史数据的离线统计分析、报表生成等场景。华为FusionInsight中的Hive在易用性、性能和安全方面进行了大量增强。
###
数据处理与存储支持服务层,通过Flume/Loader实现数据汇集,依托HDFS/HBase提供坚实存储,由YARN统一调度资源,最后通过MapReduce/Spark/Hive等引擎完成计算。这些服务相互协作,共同构成了一个完整、高效、可扩展的大数据离线批处理流水线,为上层的数据分析、挖掘应用提供了强大的基础设施支持。理解各组件定位与协作关系,是设计和优化离线处理方案的关键。
如若转载,请注明出处:http://www.gimicloud.com/product/5.html
更新时间:2026-06-19 21:30:23