大数据开发之Kafka 存储选型、数据处理与存储支持服务
在当今数据驱动的时代,Apache Kafka凭借其高吞吐、低延迟、可扩展和高可靠的特性,已成为大数据生态系统中不可或缺的基石。它不仅是实时数据管道的核心,更是流式数据处理的枢纽。本文将深入探讨Kafka在存储选型、数据处理模式以及存储支持服务方面的关键考量与实践。
一、Kafka的存储选型:日志结构的核心设计
Kafka的存储设计是其高性能的基石。其核心是一个持久化的、分布式的、分区的、可复制的提交日志(Commit Log)。
- 基于日志的存储模型:Kafka将所有消息顺序追加到日志文件中。这种“仅追加”(Append-Only)的设计,结合顺序磁盘I/O,即使在普通硬件上也能实现极高的读写吞吐量,远超随机读写。
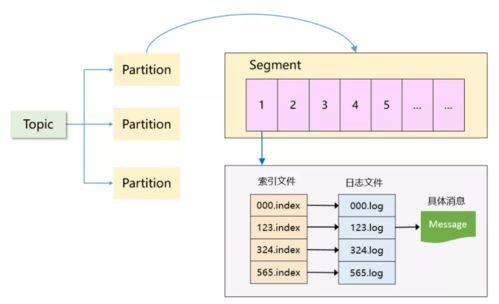
- 分区(Partition)与分段(Segment):
- 分区:每个主题(Topic)被划分为一个或多个分区,实现了数据的并行处理和水平扩展。分区是Kafka并行度的基本单位。
- 分段:每个分区在物理上由一系列顺序的、大小相等的日志分段文件(Segment)组成。当前活跃的写入文件称为活跃分段。Kafka会定期关闭旧的活跃分段并创建新的,这个过程称为日志滚动。
- 存储策略与数据保留:
- 基于时间的保留:配置
log.retention.hours等参数,删除早于指定时间的消息。
- 基于大小的保留:配置
log.retention.bytes,当分区总日志大小超过阈值时,删除最旧的分段。
- 压缩主题(Compacted Topic):对于键值对数据,Kafka提供了日志压缩功能。它只为每个键保留最新的值,从而在保证关键状态不丢失的前提下,有效节省存储空间,常用于存储数据表的变更日志(CDC)或应用程序状态。
- 存储选型考量:
- 磁盘类型:推荐使用高性能的机械硬盘(HDD)或固态硬盘(SSD)。Kafka的顺序读写特性使得高性能HDD通常已能满足需求,而对延迟极度敏感的场景可考虑SSD。
- 文件系统:EXT4或XFS是经过验证的稳定选择。XFS在处理大量文件时通常表现更佳。
- RAID配置:通常不建议使用RAID,Kafka自身的副本机制(Replication)已提供了数据可靠性。直接使用JBOD(Just a Bunch Of Disks)配置,让每个磁盘独立存储部分分区数据,能最大化I/O吞吐量和磁盘利用率。
二、Kafka的数据处理:从消息队列到流处理平台
Kafka早已超越其最初作为消息队列的定位,演变为一个完整的流式数据处理平台。
- 核心数据流模式:
- 生产与消费:生产者(Producer)将数据发布到指定主题,消费者(Consumer)以消费者组(Consumer Group)的形式订阅并拉取数据,实现解耦的、可扩展的数据传输。
- 精确一次语义(Exactly-Once Semantics, EOS):通过幂等生产者和事务API,Kafka能够确保在生产者到Kafka,以及Kafka到消费者的数据处理流程中,消息既不丢失也不重复,这对于金融、计费等关键业务至关重要。
- Kafka Connect:数据集成框架:
- 作为Kafka生态的一部分,Kafka Connect专注于与外部存储系统(如数据库、数据仓库、搜索引擎、文件系统)之间可扩展、可靠的数据导入(Source Connector)和导出(Sink Connector)。它简化了构建和管理数据管道的工作,用户无需编写代码即可实现与数百种数据源的连接。
- Kafka Streams:流处理库:
- 这是一个用于构建实时流处理应用程序的客户端库。它将流处理逻辑直接嵌入到Java/Scala应用程序中,无需额外的流处理集群。它提供了丰富的DSL(领域特定语言),支持窗口、连接、聚合、状态存储等复杂操作,并与Kafka的状态管理和容错机制深度集成。
- ksqlDB:事件流数据库:
- 建立在Kafka Streams之上的声明式SQL引擎。它允许开发者使用熟悉的SQL语句对Kafka中的流数据进行查询、转换和物化,极大地降低了流式应用程序的开发门槛,适用于实时监控、异常检测和动态仪表板等场景。
三、存储支持服务:保障数据可靠性与可用性
Kafka的强大离不开其背后一系列存储支持服务的保障。
- 副本机制(Replication):
- 每个分区的数据会被复制到多个Broker上(通过
replication.factor配置)。其中一个副本被选举为领导者(Leader),负责处理所有读写请求;其他副本作为追随者(Follower),从领导者异步同步数据。这确保了即使个别Broker宕机,数据依然可用且不丢失。
- 控制器(Controller):
- 集群中某个Broker会被选举为控制器,负责管理分区副本的领导者选举、分区重分配以及集群元数据变更等关键任务,是保障集群一致性和协调性的“大脑”。
- ZooKeeper/KRaft的协调服务:
- 传统模式:Kafka重度依赖Apache ZooKeeper来存储集群元数据(如Broker、主题、分区信息)和进行领导者选举。
- KRaft模式:这是Kafka未来的发展方向。Kafka正在移除对ZooKeeper的依赖,使用其自身实现的KRaft共识协议来管理元数据。KRaft模式简化了部署架构,提高了可扩展性和运维效率,是生产环境部署的推荐选择。
- 监控与运维:
- JMX指标:Kafka暴露了丰富的JMX指标,涵盖Broker、生产者、消费者、主题、分区等各个维度,是监控集群健康、吞吐量、延迟和积压情况的基础。
- 日志与审计:Broker日志、控制器日志、状态变更日志等是故障排查和审计追踪的重要依据。
- 工具集:Kafka提供了
kafka-topics,kafka-consumer-groups,kafka-configs等命令行工具,以及第三方运维平台(如CMAK/Kafka Manager, Confluent Control Center),极大地方便了集群的日常管理。
理解Kafka的存储设计、数据处理能力及其支持服务体系,是构建高效、稳定、可扩展的大数据实时架构的关键。从作为可靠数据总线的存储基石,到通过Connect、Streams和ksqlDB实现强大的流式处理,再到由副本、控制器和共识协议构成的坚实后盾,Kafka为现代数据密集型应用提供了从数据摄入、处理到分发的完整解决方案。开发者应根据具体业务场景(如数据吞吐量、延迟要求、语义保证、运维复杂度),做出合理的存储选型与架构设计,从而充分发挥Kafka的技术潜力。
如若转载,请注明出处:http://www.gimicloud.com/product/19.html
更新时间:2026-06-19 10:41:30